

MLOps و آینده استقرار هوش مصنوعی در سازمانها
سازمانها در دنیای امروز دیگر فقط به توسعه مدلهای Machine Learning بسنده نمیکنند. ارزش واقعی زمانی ایجاد میشود که این مدلها با موفقیت در مقیاس enterprise به محیط production منتقل شوند. اینجاست که MLOps (Machine Learning Operations) بهعنوان یک چارچوب حیاتی مطرح میشود؛ چارچوبی که مانند DevOps در نرمافزار، وظیفه دارد چرخه توسعه تا استقرار مدلهای هوش مصنوعی را پایدار، قابل اعتماد و تکرارپذیر کند. در این مقاله، به بررسی عمیق اجزای فنی، ابزارها، چالشها و آینده MLOps میپردازیم.
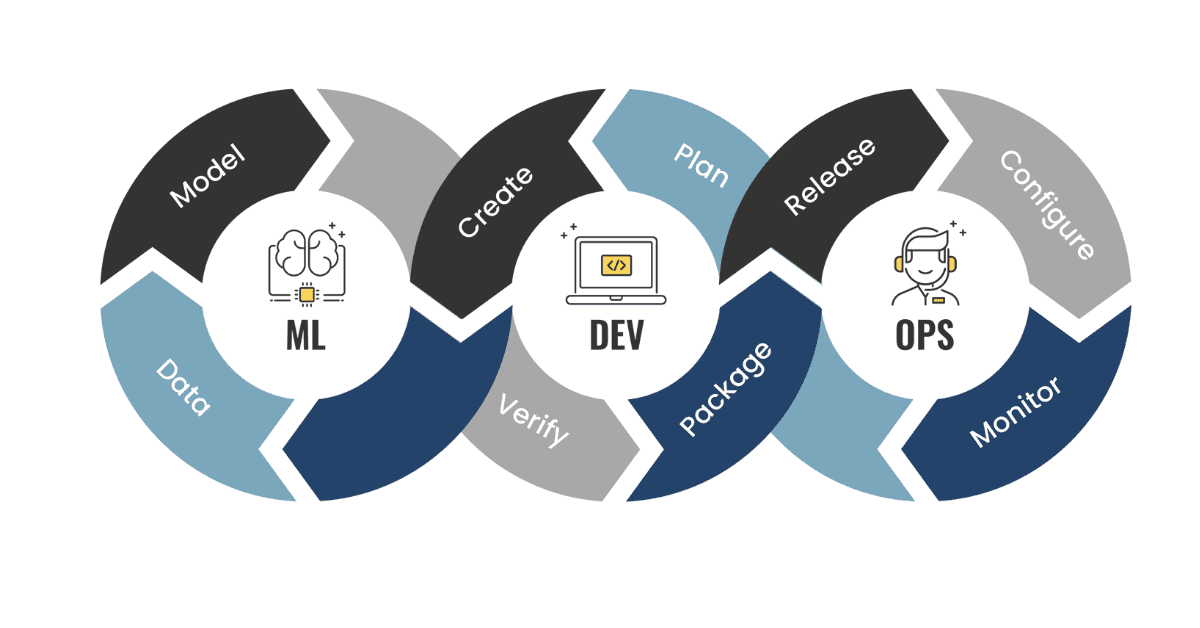
چرخه عمر MLOps
چرخه عمر MLOps شامل مراحل متوالی و تکرارشونده است که از data ingestion آغاز و به continuous monitoring ختم میشود. هر مرحله نیازمند ابزارها و رویههای دقیق است:
- Data Ingestion & Validation: جمعآوری داده از منابع متنوع (SQL، APIs، IoT) و تضمین کیفیت آنها با ابزارهایی مثل TFT Data Validation.
- Feature Engineering: استخراج ویژگیها با Feature Storeهایی مانند Feast.
- Model Training & Experiment Tracking: مدیریت آزمایشها با MLflow یا Weights & Biases.
- Deployment: استقرار روی Kubernetes با Seldon یا BentoML.
- Monitoring & Feedback: پایش performance، تشخیص drift و loop بازخورد.
نقطه تمایز MLOps با فرآیندهای سنتی ML در این است که به جای «پروژهمحور» بودن، نگاه «محصولمحور» دارد. یعنی مدل ML مانند یک محصول زنده دیده میشود که نیاز به release cycle، versioning و rollback دارد.
ابزارها و پلتفرمهای کلیدی
تنوع ابزارها در MLOps زیاد است، اما مهمترینها عبارتند از:
- Kubeflow: اجرای pipelineهای ML در Kubernetes. مناسب برای سازمانهایی با نیاز به مقیاس بالا.
- MLflow: مدیریت آزمایشها، مدلها و deployments. گزینهای سبکتر برای شروع.
- TFX (TensorFlow Extended): pipeline end-to-end برای کاربرانی که روی TensorFlow متمرکز هستند.
- Seldon / BentoML: فریمورکهای استقرار مدلها در محیطهای real-time.
- Evidently AI: مانیتورینگ drift و کیفیت مدل.
زیرساخت و معماری مرجع
اجرای MLOps بدون زیرساخت مناسب غیرممکن است. معماری مرجع شامل سه لایه کلیدی است:
- Data Layer: ذخیرهسازی داده در Data Lakehouse (مثل Delta Lake یا BigQuery).
- Model Layer: آموزش مدلها روی GPU/TPU clusters با orchestration توسط Kubernetes.
- Serving Layer: استقرار مدلها روی REST/gRPC endpoints، یا edge devices.
اتصال این سه لایه از طریق CI/CD pipelines و Infrastructure-as-Code (Terraform, Helm) مدیریت میشود.
چالشهای اصلی
برخی از مهمترین موانع در پیادهسازی MLOps عبارتند از:
- Data Silos: دادههای غیر یکپارچه در واحدهای مختلف.
- Reproducibility: نتایج مدل باید در محیطهای مختلف تکرارپذیر باشد.
- Scalability: مدل باید برای میلیونها request همزمان پاسخگو باشد.
- Collaboration: نیاز به همکاری Data Scientist و Engineerها با یک زبان مشترک.
- Cost Optimization: هزینه GPU/TPU و storage باید مدیریت شود.
مدیریت Drift و مانیتورینگ
مدلها پس از استقرار به مرور با پدیده Data Drift (تغییر توزیع دادهها) و Concept Drift (تغییر رابطه ورودی و خروجی) روبهرو میشوند. عدم مدیریت drift منجر به کاهش accuracy و افزایش ریسک تصمیمهای اشتباه میشود.
ابزارهایی مانند Evidently AI یا ماژولهای drift detection در TFX و Seldon کمک میکنند کیفیت مدلها بهطور مداوم پایش شود. برخی سازمانها حتی shadow deployment را اجرا میکنند تا مدل جدید در کنار مدل فعلی تست شود و performance واقعی مقایسه گردد.
امنیت و Governance
مدلهای ML نیز هدف حملات قرار میگیرند. تهدیداتی مثل Model Inversion (بازیابی دادههای آموزشی از مدل) یا Data Poisoning (آلودگی دادهها) جدی هستند.
راهکارها شامل: - Role-Based Access Control (RBAC) - نگهداری audit trail تغییرات مدل - AI Governance frameworks مانند NIST AI RMF یا ISO/IEC 23894
سازمانها باید همانطور که برای اپلیکیشنها DevSecOps دارند، برای مدلها نیز MLSecOps پیادهسازی کنند.
Case Study: Uber، Google و Microsoft
Uber: با پلتفرم Michelangelo چرخه کامل ML از data prep تا serving را خودکار کرده است. این پلتفرم به بیش از ۱۰۰۰ مدل فعال در سرویسهای Uber قدرت میدهد. Google: با ترکیب TFX و Kubeflow، میلیونها مدل را در Google Ads و YouTube مدیریت میکند. Microsoft: Azure Machine Learning قابلیتهای end-to-end برای MLOps ارائه میدهد و tightly integrated با Azure DevOps است.
این نمونهها نشان میدهند که MLOps تنها یک ترند نیست، بلکه ستون فقرات AI در مقیاس enterprise است.
چشمانداز آینده
آینده MLOps در سه حوزه اصلی خلاصه میشود:
- LLMOps: مدیریت lifecycle مدلهای زبانی بزرگ (LLMs) با focus بر hallucination detection و data privacy.
- Edge MLOps: استقرار مدلها روی edge devices (مثل IoT, 5G nodes) با latency پایین.
- Responsible AI: تمرکز بر fairness، explainability و compliance با مقررات (EU AI Act).
سازمانهایی که از امروز روی این سه حوزه سرمایهگذاری کنند، در آینده در خط مقدم رقابت دیجیتال خواهند بود.
جمعبندی
MLOps دیگر یک انتخاب نیست، بلکه لازمهی موفقیت پروژههای AI در مقیاس سازمانی است. این رویکرد باعث میشود مدلها نه فقط در محیط آزمایش، بلکه در production پایدار و ایمن باقی بمانند. سازمانهایی که چرخه MLOps را پیادهسازی کنند، توانایی پاسخ به تغییرات سریع دادهها، تهدیدات امنیتی و نیازهای بازار را خواهند داشت.
نویسنده